
Introduction
Large Language Models (LLMs) like OpenAI’s ChatGPT and Google’s Gemini have revolutionised the way we interact with information. They can generate human-quality text, translate languages, write different kinds of creative content, and answer your questions in an informative way.
However, while these models are powerful, they often fall short when it comes to providing highly specific or personalised responses. This is especially true when you need information that’s deeply rooted in your company’s data, such as internal documents, product catalogues, or employee records.
For example, at Sping we have done projects for over 20 years. What if we want to know whether we once did a project in the healthcare branch.
Searching for ‘healthcare’ could give some hits, but projects with themes like ‘medicines’ and ‘doctor’ would not be listed while they are related. Also, asking a LLM with only general knowledge would not work obviously.
The Challenge of Context Windows
You can manually add some PDF files that probably contain the information you need when entering your prompt. But what if you do not know where to look for specifically, and you would rather just have all the information available.
In our example, we may have documented about relevant projects in our knowledge base, it can maybe only be an orientation in an email conversation or in a presentation of our weekly company updates.
So lets add all company data, emails, presentations to the prompt, right? Unfortunately this is not possible.
One of the primary limitations of LLMs however is their context limit. This refers to the amount of tokens (more or less to the number of words) the model can process and consider when generating a response. For instance, ChatGPT typically has a context window of around 4000 tokens, while Gemini offers a more generous limit of 32000 tokens. However, even with these larger windows, it’s often not enough to encompass all the relevant information for complex queries.
Retrieval Augmented Generation
To overcome this limitation, a technique known as Retrieval Augmented Generation (RAG) has emerged as a little ‘trick’. RAG combines the power of LLMs with vector databases to provide more comprehensive and relevant responses.
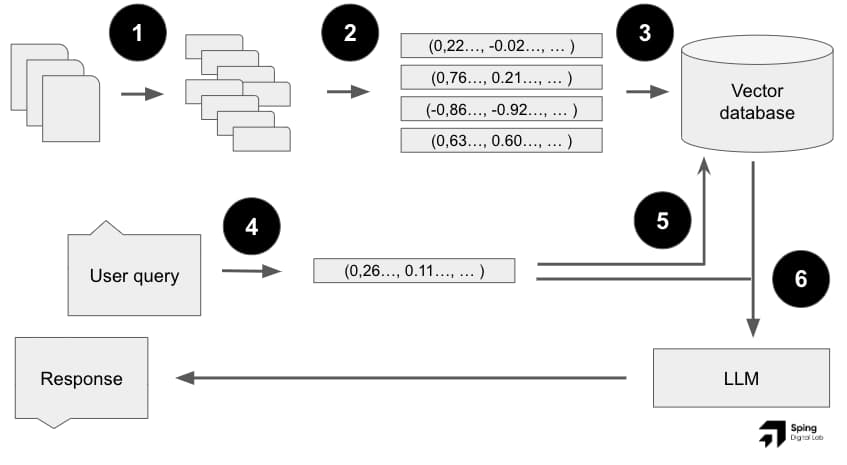 The Retrieval Augmented Generation flow as described below
The Retrieval Augmented Generation flow as described below
How Does RAG Work?
- Chunking your documents
- Your documents (e.g., PDFs, Word documents, JSON files, anything) are broken down into smaller chunks.
- Embedding Creation
- Each chunk is converted into a numerical representation called an embedding. This embedding captures the semantic meaning of the text.
- Think of these embeddings as coordinates in a high-dimensional space. Similar documents will have embeddings that are closer together.
- Vector Database
- These embeddings are stored in a specialised database called a vector database.
- This database is optimised for efficient searching based on similarity.
- Query Embedding
- When a user asks a question, their query is also converted into an embedding.
- Retrieval
- The vector database is searched to find the embeddings that are most similar to the query embedding.
- This identifies the most relevant documents or passages.
- Augmented Response
- The user’s query and the retrieved documents are then fed into the LLM.
- The LLM generates a response that is informed by both the query and the additional context provided by the retrieved documents.
In our example, the result of the relevant chunks for our query will be parts about words that are found to be close to ‘healthcare’, ‘project’ and the LLM will finish the task by responding to the actual prompt. It found an article on our website about a CMS for medical guidelines, and also the internal note of Jan Gerard’s visit to Sammanté Health in Senegal.
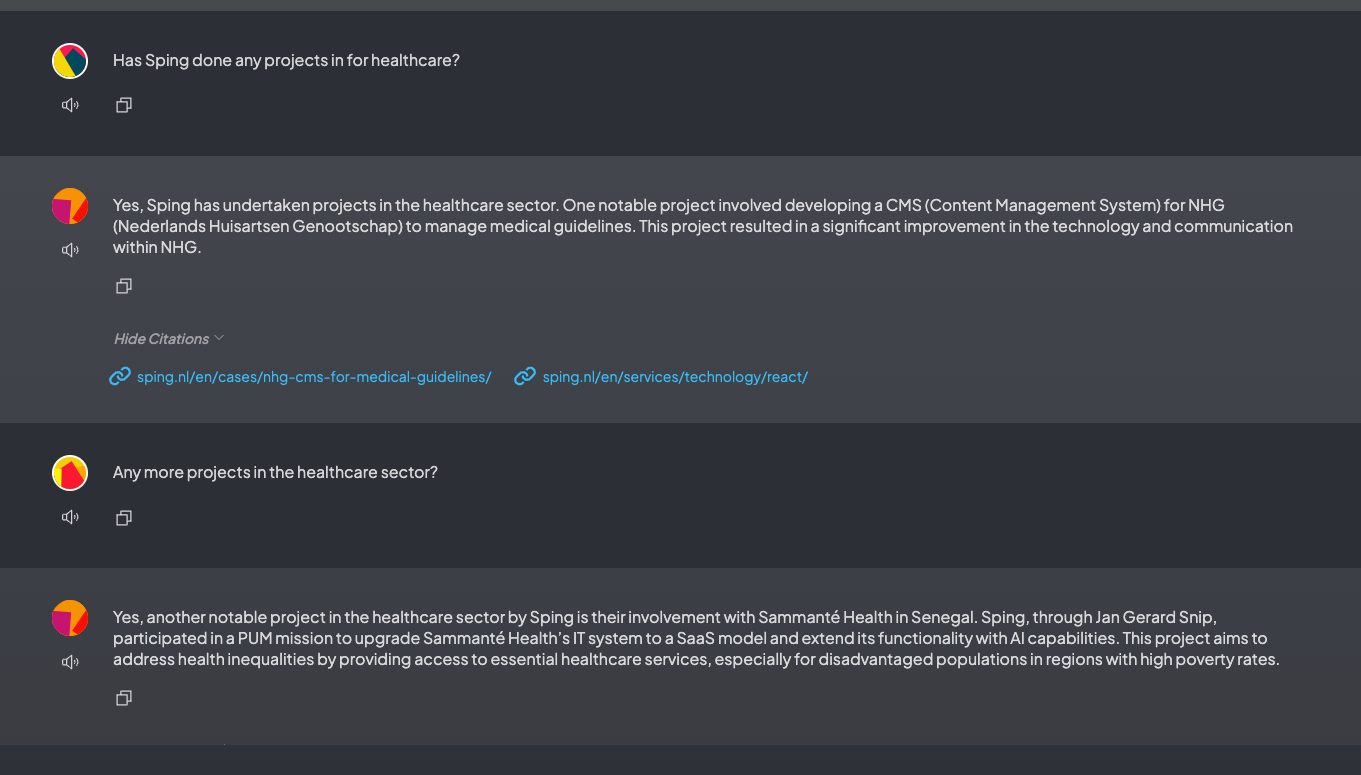 An example conversation with the augmented LLM
An example conversation with the augmented LLM
Conclusion
Retrieval Augmented Generation offers a promising solution for enhancing the capabilities of Large Language Models. By combining the power of LLMs with vector databases, you can search your own data in a more powerful way, but it does not work perfectly out of the box. There are still challenges in connecting all data to your database and tweaking the prompts so you get the results you want. It does, however, show the interesting movement of using AI in all sorts of problems. For example in our case, having a backup for the ‘he knows all about everything’ persons in your organisation.