
At Sping, we work with a number of clients who share a common workflow: their inspectors take pictures as proof of measurements, then manually enter the measured value into an app.
Imagine, for instance, weighing a box of grapes and recording the weight along with a picture in the app. This process can be repetitive and time-consuming. We explored the potential idea to leverage image extraction to streamline this workflow and improve efficiency for inspectors.
Exploring a Low-Level Approach
Initially, we opted for a low-level solution using Tesseract, an open-source Optical Character Recognition (OCR) engine. The appeal of this approach was its ability to run locally, potentially even offline. While Tesseract performed well for standard text blocks, it struggled with the specific challenges of our use case:
- Seven-segment displays: Tesseract is not optimized for the specific format of seven-segment displays, commonly used in measurement devices.
- Image quality variations: Pictures taken at angles or with dirty device screens presented further hurdles for accurate extraction.
Tesseract would require significant pre-processing to function effectively, making it a less than ideal solution.
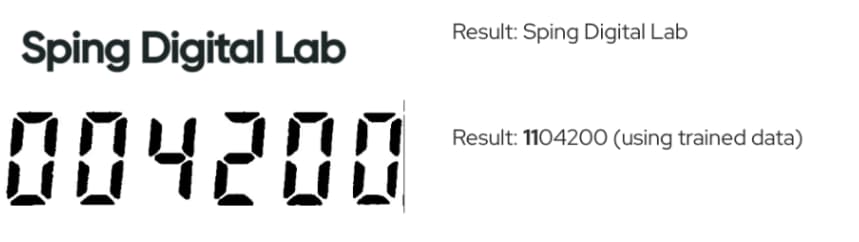 Results using Tesseract on Regular text and seven-segment displays
Results using Tesseract on Regular text and seven-segment displays
Moving to the Cloud: Google Cloud Vision
For these reasons, we decided to explore a cloud-based solution: Google Cloud Vision. This API offers a variety of features, including object labeling, face detection, and, most importantly for us, text detection. We set up a Google Cloud project with Cloud Vision and connected it to a simple demo application, aptly named “Extraction Eagle.”
Extraction Eagle allowed users to upload an image and select the relevant extracted text to be used as the input value. The demo successfully demonstrated the potential of the Cloud Vision API for our purposes. However, it also highlighted the need for human validation or correction. Extracted text was not without errors, especially in cases of dirty measurement devices that could lead to misleading readings. Additionally, the API detected all text within the image, including irrelevant details like the brand of the device. Further development would be required to focus on extracting only the information of interest to the user.
 Demo application
Demo application
Conclusion
Our exploration of image extraction has shown its promise for improving data collection workflows. While a low-level approach like Tesseract has limitations, cloud-based solutions like Google Cloud Vision offer a more robust option. However, it’s important to remember that such solutions require further development to ensure data accuracy and filter out irrelevant information.